I present you with my restructured project on options trading and scenario analysis. You are more than welcome to try it out. Firstly, I will give a small presentation that will reveal what you can do with it and whether you need to continue reading. Then I will continue with dependencies, classes used and classes created along with methods defined. Finally, I will give some basic operations to show how you can use it yourself.
Lets say you are constructing a portfolio. You want to start with risk-reversal strategy(buy call high, sell put low). You are interested in payoff chart:
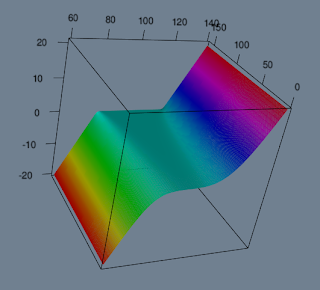
For some reason you decide to short a stock and add it to your portfolio:
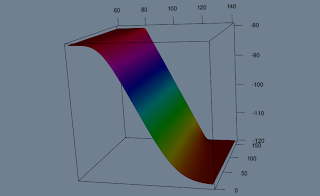
You now realise that you must really have negative view on the market to trade this. You decide that this will be your view, but your neighbour tells you that a sharp price increase is possible. Decide to buy some digitals:
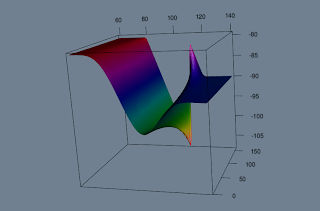
You are satisfied with your decisions and would like to check you profit and loss as up to now numbers on z axis just showed payoff. Remember as you shorted the stock, you've got some cash. In particular 100. But your digitals cost and sum of option prices should be slightly positive as both symmetrically out of the money:
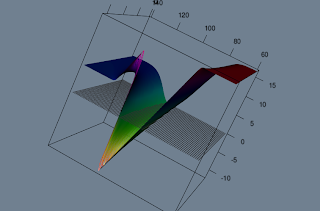
While you are very happy with your decisions you also want to investigate some sensitivities. Say vega:
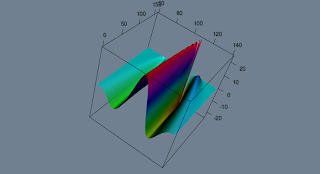
Now you're like:"Not trading this weird thing".
If you liked what you saw and you want to try it yourself or even contribute, continue reading.
"sa_work.R" is the file where you would normally work. It has only 1 line to call all you need:
source("~/core/Projects/scenario_analysis/0_sa_init.R")
This is the only line you need to change once you have repository downloaded. Just locate "0_sa_init.R" and it will do all. And by all I mean 2 things: load packages, load other scripts and couple of basic parameters.
Dependencies:
"quantmod" might be needed if you want to download some option or stock data from yahoo. "RQuantLib" is not currently used, but pricing functions might be taken from it later to price americans. "fields" was used in earlier version for interpolation over scatter and might be needed in later development. "rgl" - 3d graphics. "lubridate" is not essential, but it makes life easier when working with dates at user level. However all date objects are automatically converted to "timeDate" class.
File structure is simple:
"0_funs" folder with 2 scripts loaded from it "0_basic.R" that contains some basic functions - only 2 out of 5 are really needed. And "0_inst.R" - abbreviation for instruments, but now contains all the project within. Surprisingly only 500 lines of code. Went down twice after I drifted to OOP approach.
"2_structure_int.R", "2_structure_vol.R" will be used for interest rate structure and implied volatility surface implementation in the future and are currently not used.
Classes:
Classes used are S4 for outputs, some simple variables that needed formalisation and parameter objects. Reference classes are used for instruments.
S4:
"currency" inherits from "character" and Currency() function makes sure its of length 3 and creates new.
"gen.par" contains number of preferred working days in a year and list of interest rates.(later could be extended to interest rate structure).
"stock.par" contains all parameters that are stock specific and varies over time.
"scatter" inherits from "matrix". Contains output from reference classes: data, row and column variables.
Reference:
"security" superclass of all securities.
"spot", "forward" and "option" inherits from "security".
All of them have same methods: price, delta, gamma, theta, rho, rhoQ, vega. All of them have arguments: st(stock price), tVec(time), vol(volatility). "option" class has additional method: getiv.
Here is the list of functions you need:
time_seq(from, to, by = "hour", rng = c(9, 16), holiday = holidayNYSE(2013:2020), trading = TRUE)
- creates time sequence. All methods round the time to hourly so don't use higher frequency! Also, avoid using daily, just stick to default until you know what you are doing.
GenPar() - creates "gen.par" object named "gen.par" and assigns it to "gen.par" environment.
lsg() gets you gen.par object
StockPar() - analogous to GenPar, just names it paste0(ticker,".par")
lss() - lists objects in "stock.par" environment
rms() - clears "stock.par" environment
Spot(id, num=1, class="equity", cur="usd"),
Forward(id, underlying, maturity, K, num=1, class="equity", cur="usd"),
Option(id, underlying, maturity, K, put, ame=0, type="vanilla", num=1, extra=list(0), class="equity", cur="usd")
- creates security objects and assigns it to "securities" environment.
lsi() - lists objects in "securities" environment
rmi() - clears "securities" environment
vaSecurities() - collects all objects in "securities" environment in a list.
Good news. this is all you need. Few things to note. All strings are converted to CAPS including object names for instruments. Only security class is equity. Only 2 option types are available: "vanilla" and "binary"(cash-or-nothing). All options are european.
source("~/core/Projects/scenario_analysis/0_sa_init.R")
########################################################################
GenPar(
rates = list("USD"=0.05),
nyear = 252
)
StockPar(
ticker = "aapl", # ticker of the stock
s0 = 100, # current price of the stock given time(date below)
vol = 0.3, # yearly vol(numeric)
d = 0, #
date = Sys.Date() # converted "timeDate": you can enter this in many formats, say: 20120714
)
########################################################################
# Spot("AAPL")
# Forward("AAPLF", "AAPL", Sys.Date()+days(30), 110)
# Option("AAPLC", "AAPL", Sys.Date()+days(30), 100, 0, 0, type="binary", num=1)
Spot("AAPL", num= -1)
Option("AAPLC", "aapl", Sys.Date()+days(30), 120, 0, 0, type="vanilla", num= 1)
Option("AAPLP", "aapl", Sys.Date()+days(30), 80 , 1, 0, type="vanilla", num=-1)
Option("AAPLB", "aapl", Sys.Date()+days(30), 110 , 0, 0, type="binary", num=30)
t <- time_seq(Sys.Date(),Sys.Date()+2)
s <- seq(80,120,10)
v <- seq(0.1,0.5,0.1)
AAPLC$price() # current price [1,] 0.05804536
AAPLC$delta() # current delta
AAPLC$getiv(AAPLC$price()) # [1] 0.3000074
# say you observe the price higher in the market: 0.1!
AAPLC$getiv(0.1) # [1] 0.3263369
# assign it to stock parameter!
AAPL.par@vol <- AAPLC$getiv(0.1) # you have correct volatility now
p1 = AAPLC$price(st=s, tVec=t) # use st with tVec
p2 = AAPLC$price(vol=v, tVec=t) # or vol with tVec
p3 = AAPLC$price(vol=v, st=s) # DON'T use st with vol
str(p1)
# Formal class 'scatter' [package ".GlobalEnv"] with 4 slots
# ..@ .Data: num [1:5, 1:8] 1.63e-06 8.97e-04 5.80e-02 8.34e-01 4.28 ...
# ..@ rows : num [1:5] 80 90 100 110 120
# ..@ rows2: num 0.3
# ..@ cols : num [1:8] 0.0794 0.0789 0.0784 0.0779 0.0774 ...
# the output is the same("scatter") from all methods except "getiv"
class(p1) # scatter
plot(p1)
class(p1+20) # scatter
b1 = AAPLP$price(st=s, tVec=t)
# sum the payoffs
class(p1+b1) # matrix - not good
plot(p1+b1) # not a good idea
class(sum(p1, b1)) # scatter - stick to this
plot(sum(p1, b1))
# sum creates new "scatter" object
# and all attributes are taken from 1st object!
# MEANS: never put a "spot" object first as due to the fact,
# that it does not have maturity, time axis will be incorrect!
cost <- as.numeric(sum(AAPLC$price(), AAPLP$price(), AAPL$price(), AAPLB$price()))
cost # [1] -96.04445 means you have cash!
port <- sum(AAPLC$price(s,t), AAPLP$price(s,t), AAPL$price(s,t), AAPLB$price(s,t))
plot(port-cost) # here is your proffit and loss!
vega <- sum(AAPLC$vega(s,t), AAPLP$vega(s,t), AAPL$vega(s,t), AAPLB$vega(s,t))
plot(port-cost) # and here is your vega
# make parameters longer and finer to generate nice graphs:
t <- time_seq(Sys.Date(),Sys.Date()+30)
s <- seq(80,120,1)
# and repeat
Try it out. Your opinions on flaws, mistakes or improvements are more than welcome.
https://github.com/afraid2trade/SCENARIO_ANALYSIS.git









